Was ist ein Index? (Teil 2)
Im ersten Teil haben wir kurz gezeigt was ein Baum ist und wie er funktioniert. Jetzt geht es darum wie der SQL Server damit umgeht.
Heap vs. Index
Eine Tabelle im SQL Server kann auf zwei unterschiedliche Arten gespeichert werden. Als Heap oder als Index. Wird die Tabelle als Index gespeichert spricht man hierbei dann vom Clustered Index. Ein Clustered Index ist also die Tabelle selbst. Insofern kann es ihn auch nur einmal geben pro Tabelle. Der Clustered Index beinhaltet alle Spalten der Tabelle. Aber nicht alle Spalten sind Teil der Sortierung. Als Schlüssel innerhalb des Index kann eine oder mehrere Spalten fungieren. Theoretisch könnten auch alle Spalten der Tabelle Teil des Schlüssels sein. Dies kann bei kleineren Tabellen durchaus der Fall sein. Im Normalfall wird der Schlüssel für den Clustered Index aber aus wenigen Spalten gebildet. Oftmals wird sogar eine extra Schlüsselspalte hinzugefügt mir einem nummerischen Wert. Hier wird entweder ein zufälliger Wert eingetragen der Systemweit eindeutig ist oder es wird automatisch mit jedem neuen Eintrag hochgezählt.
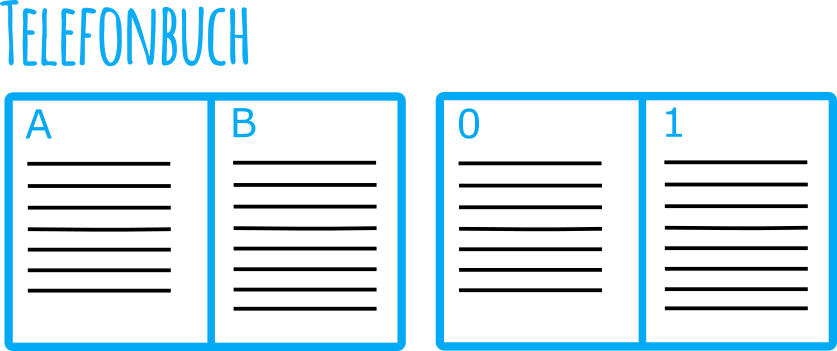
Mit dem Clustered Index kann nur ein Sortierungsfall abgedeckt werden. Betrachten wir mal als Beispiel eine Tabelle mit Adressen. Hier könnten wir als Schlüssel für den Clustered Index den Nachnamen und zusätzlich den Vornamen nutzen um danach schnell suchen zu können. Wenn wir nun nach einen Namen in der Tabelle suchen finden wir schnell den oder die passenden Einträge weil wir den Clustered Index für die Suche nutzen können. Wollen wir an Hand einer Telefonnummer den Namen finden hilft uns der Clustered Index erstmal nicht weiter. Wir müssen alle Einträge durchsuchen bis wir die Telefonnummer gefunden haben und können dann den Namen auslesen.
Wir wissen, dass Telefonnummern eindeutig sind und würden wenn wir händisch suchen aufhören wenn wir einen passenden Eintrag gefunden haben. Der SQL Server weiß erstmal nicht, dass Telefonnummern eindeutig sind und muss wirklich alle Einträge durchsuchen, da er wenn er einen Eintrag gefunden hat nicht sagen kann, dass kein weiterer passender Eintrag mehr kommt. Der letzte Eintrag könnte aus Sicht des SQL Servers auch nochmal die gleiche Telefonnummer beinhalten. Im SQL Server nennt man diese Art des Suchens Index Scan. Ein Index Scan bedeutet immer, dass alle Einträge gelesen werden. Wird im Gegenzug ein Index Seek verwendet kann der Baum des Index verwendet werden und mit wenigen Zugriffen der passende Eintrag gefunden werden. Wenn kein Clustered Index vorhanden ist kann auch kein Index Seek oder Index Scan stattfinden. Bei einem Heap gibt es keinen Seek, da hier kein Baum vorhanden ist der durchlaufen werden kann. Hier gibt es nur den Scan und er heißt beim Heap Table Scan.
Ob ein Heap oder ein Clustered Index für eine Tabelle verwendet wird ist ein Punkt der beim Design der Tabelle gut überlegt werden sollte. Je nach Datenbanksystem herrschen hier unterschiedliche Präferenzen vor. Zusätzlich muss die Art der Daten und die Zugriffsweise auf die Daten beachtet werden. Werden Daten häufiger gelesen wird oft ein Clustered Index verwendet. Wenn Daten überwiegend geschrieben werden kann der Heap oft seinen Vorteil beim Schreiben ausspielen. Auch ein Heap kann performanter gemacht werden beim Lesen. Wie das geht zeige ich in Teil 3 von „Was ist ein Index?“. Im Bereich Microsoft SQL Server überwiegt der Einsatz von Clustered Index. Ob das wirklich immer der sinnvolle Weg ist muss im Einzelfall entschieden werden. Das Wissen über die Funktionsweise ist hier nur ein Punkt der in die Entscheidung einfließen sollte.